The Overview
Modern CPUs improve performance using pipelining, where multiple instructions are processed in overlapping stages instead of one at a time. This increases throughput, but it introduces challenges when instructions depend on each other or when memory access becomes a bottleneck.
To address this, this project models a 16-bit RISC-V CPU that simulates realistic instruction flow and memory interaction. Built in C++, the system extends a trace-driven architecture by introducing a Reorder Buffer (ROB) and Load Store Buffer (LSB), allowing instructions to be tracked, scheduled, and completed efficiently. The design focuses on maintaining correctness while improving execution efficiency under constrained resources.
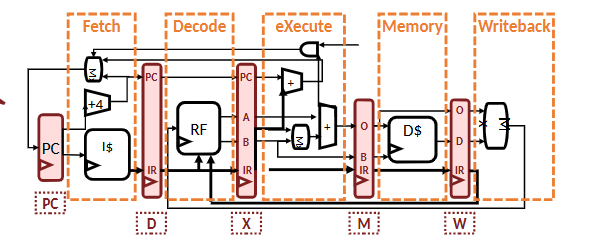
CPU pipeline diagram — commit, forwarding, and in-order retirement stages.
Out-of-Order Execution
Out-of-order execution allows instructions to run as soon as their required data is available, rather than strictly following program order. This reduces idle cycles and improves overall CPU utilization.
In this design, instructions are dynamically allocated into the ROB and LSB, where they can execute and commit independently. Loads are optimized using store-to-load forwarding within the buffer, reducing unnecessary memory accesses. A Tomasulo-style scheduling approach is used to manage instruction readiness and resource allocation, while ensuring that final retirement still occurs in order to preserve correctness.
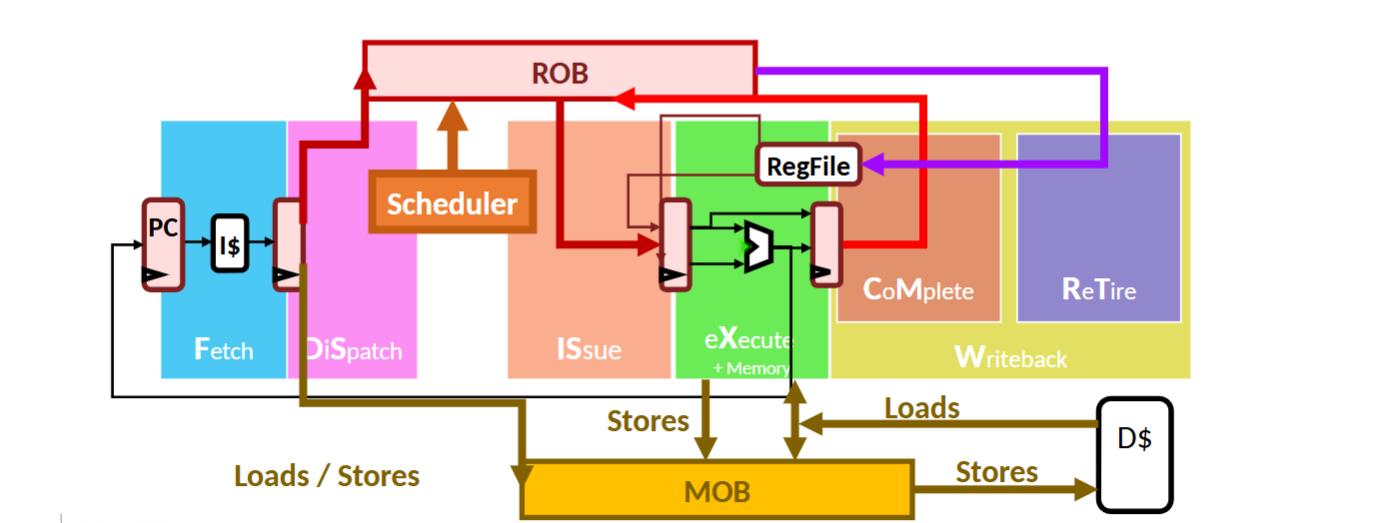
Reorder Buffer and Load Store Buffer managing speculative execution.
Results & Learnings
The implementation demonstrates a significant improvement in execution efficiency compared to an in-order baseline. By enabling out-of-order execution and buffering mechanisms, the CPU achieves up to 2–3× higher IPC (Instructions Per Cycle) under memory-bound workloads.
This project reinforces how key architectural components—such as the ROB and LSB—help hide memory latency and improve throughput. It also highlights the balance between complexity and performance, showing how even simplified models can capture the core behavior of modern processors while remaining computationally manageable.
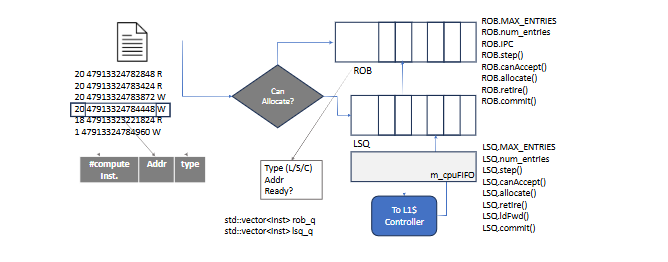
Reorder Buffer and Load Store Buffer program block diagrams.
View on GitHub →