The Overview
This project focuses on building a neural network inference engine and optimizing it for both CPU and GPU execution. The main idea is to understand where performance bottlenecks come from in real workloads, especially in matrix multiplication, which dominates most neural network computations. The system is tested using a simple MNIST-trained model and implemented in both dense and sparse formats. This makes it possible to compare how things like memory access patterns, sparsity, and compute optimizations affect overall runtime and efficiency.
CNN architecture — layer breakdown and tensor flow.
CUDA Kernels
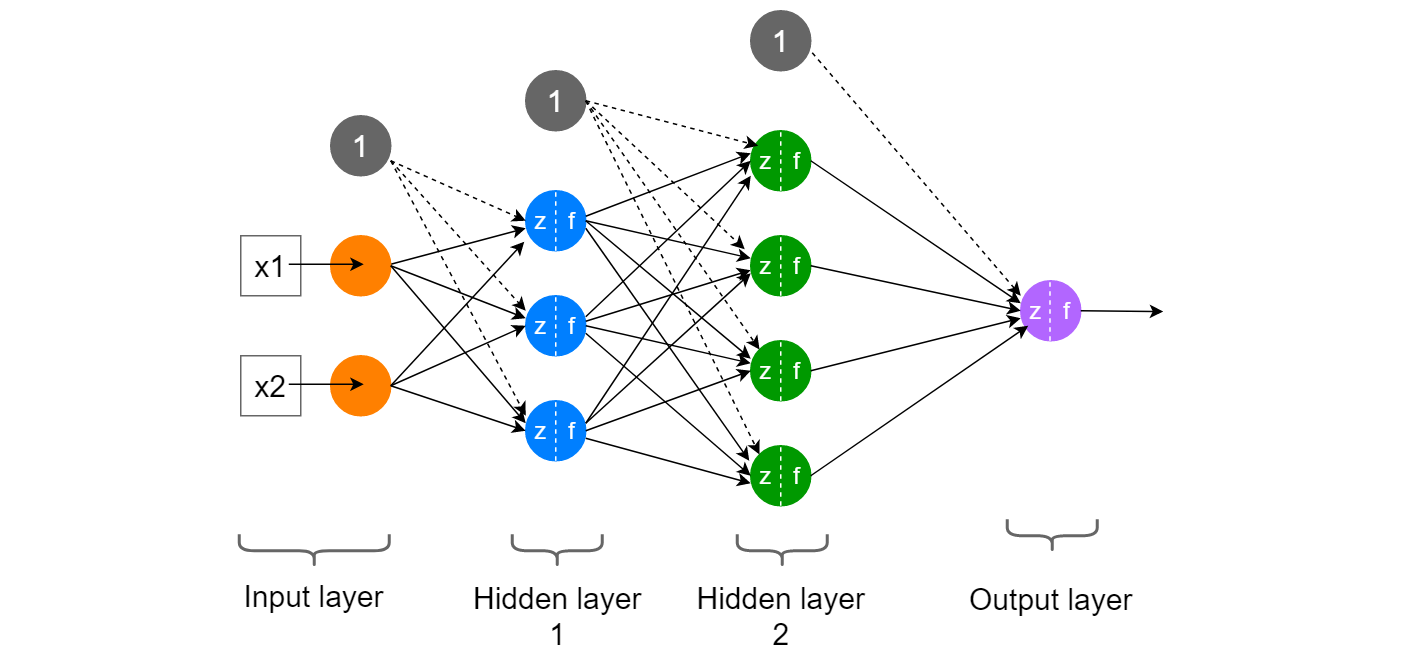
The model used here is a basic 2-layer neural network for MNIST classification. It takes input features, passes them through a hidden layer with a tanh activation, and then produces outputs using a sigmoid activation. The final prediction is selected using argmax.
Even though the architecture is simple, everything is built around matrix-vector and matrix-matrix operations, which makes it a good setup for testing optimized linear algebra implementations. The same structure is used for both dense and sparse versions so performance differences come only from the implementation, not the model itself.
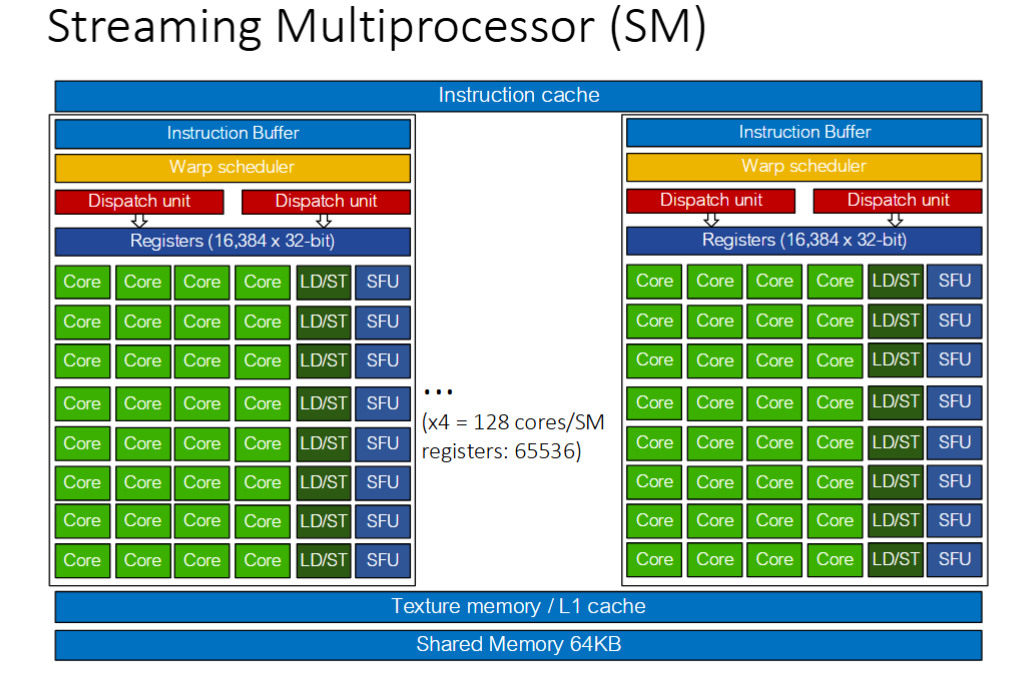
Custom CUDA kernel implementation for vectorized tensor operations.
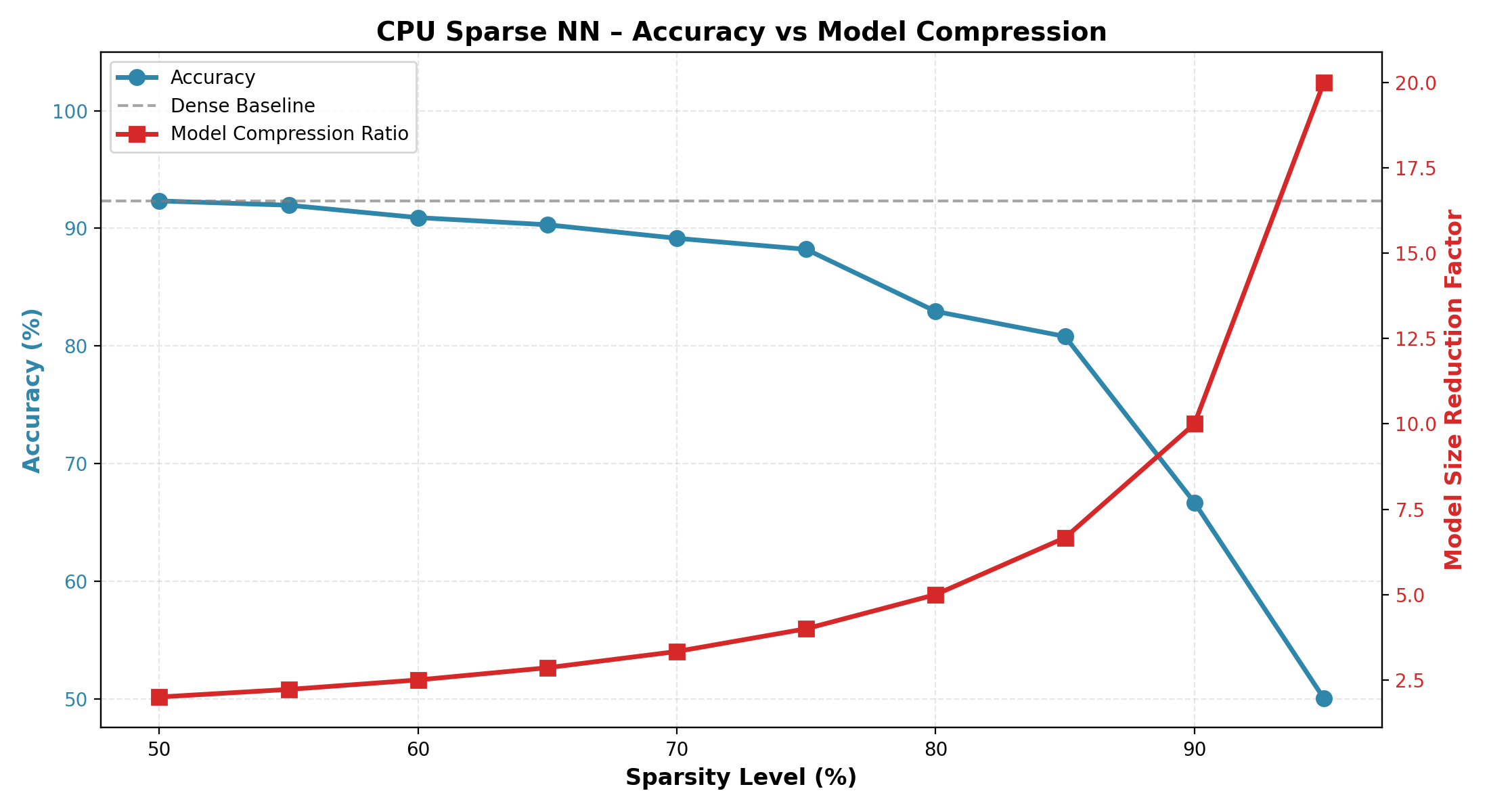
Performance Profiling
The system was benchmarked across CPU and GPU, as well as dense and sparse configurations. On the CPU, performance is mostly limited by memory bandwidth and cache efficiency, especially for larger matrix sizes. On the GPU, parallel execution gives much better performance, particularly for large workloads and sparse operations. Sparse models reduce computation significantly at higher sparsity levels, but this comes with some accuracy trade-offs. Overall, the results clearly show how sparsity and hardware optimization impact runtime, with GPU implementations giving the strongest speedups across most cases.